I have chosen the most basic use-case in Enterprise Search: provide a secure search experience to users.
FAST ESP System has the following components:
- Connector
- Document Processing Pipeline
- Security Access Module (SAM)
- Query and Results processing Server

A specific connector is used to index content from different content sources. For example, a Lotus Notes connector is used for indexing Notes content.
Each Connector is assigned to a single document processing pipeline. Document processing pipeline consists of multiple stages which process the content fed from the connector. Example stages: stemming, entity extraction, short summary generation etc
Security Access Module has the following components:
- User monitor - stores the user group information
- ACL monitor - provides the ACL information for the content
- Search filter generator - creates the query filter using user and groups info to filter documents
- Last minute access rights - performs a last min check on the results returned to drop unauthorized results
As the content fed from connector passes through the document processing pipeline, for content stores like filesystem, ACL information is pulled for each document using ACL monitor and added as additional metadata to the document. After passing through all the stages the document is added to the binary search index.
Search:

When a search is run from the UI, the front end application adds the userid information to the query and passes it to QR server. QR Server consists of two modules, query processing and results processing. When a search query is passed along to the QR Server it goes through the query processing stages which can be customized and include spellcheck, synonym expansion and importantly security filter generation. In the security filter generation stage, the userid and domain info passed from search UI is sent to the Search filter generator in SAM and Search filter generator in turn communicates with User monitor and returns a security filter which can then be added to the original query.
ESP also provides a last minute security check called from a result processing stage. Though supported by all security types, this is useful for applications handling highly-secured content where real-time security check is required.
Autonomy IDOL System is mostly similar with a few differences. Main components in Autonomy IDOL:
- Connector
- Group Server
- IDOL proxy

Autonomy IDOL system has various connectors for indexing content for example, lotus notes connector, documentum connector etc. IDOL provides a powerful import filters mechanism to process the content indexed by the connectors. Index tasks are a way of adding more metadata or manipulating existing metadata from external systems. After passing through the import jobs and index tasks the document is indexed into a binary index in IDOL server.
Search:
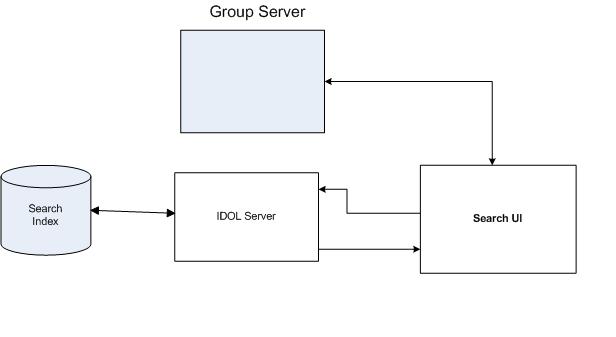
Unlike QR server adding the security filter in ESP, in IDOL applications, the search front-end makes the call to the group server and gets the security filter and adds it to the query sent to the IDOL Server.
Group Server maintains the user and group information for various repositories whose content is indexed into IDOL server. Calling search application passes the userid to the Group server which then generates an encrypted security string merging the user&group info from all repositories using aliasing.
The Role of QR Server and to some extent Document Processing Pipeline in the ESP system is handled directly by the IDOL server. IDOL server provides many configurable parameters which enable fine tuning the system based on user needs.
